LLM 作业 - 第二周(二)
在上一篇文章中,我们使用conda,新建了一个叫做cs146s的python环境,并且成功开启了应用
以下是使用的命令
1 | |
在这篇文章中,我们继续学习
待办项 1:搭建新功能框架
第一步,分析extract.py
脚本功能完整分析
我来为你逐部分拆解这个 Python 脚本的核心作用、工作原理、设计逻辑,让你完全理解它的用途。
一、整体核心作用
这是一个文本动作项提取工具,专门用于从任意文本中自动识别、清洗、去重并提取出待办事项、行动指令、任务项,最终返回一个干净、无重复的任务列表。
简单说:把杂乱文本里的“要做的事”自动挑出来。
二、脚本依赖与环境
- 基础库:
os/re/typing(正则匹配、类型注解) - 工具库:
json/dotenv(环境变量加载) - AI 相关:
ollama(可调用本地大模型,本脚本未实际使用) - 核心能力:纯文本规则匹配 + 启发式算法
三、逐模块功能拆解
1. 常量定义(匹配规则)
1 | |
✅ 作用:定义识别任务行的基础规则。
2. 核心判断函数:_is_action_line()
判断某一行文本是不是任务/行动项,满足任一条件即为是:
- 以项目符号(- * • 1.)开头
- 以
todo:/action:/next:开头 - 包含复选框标记
[ ]/[todo]
✅ 作用:精准识别标准格式的待办事项。
3. 主函数:extract_action_items()(最重要)
这是脚本的入口函数,完整处理流程:
- 按行拆分文本
- 逐行判断是否为任务行
- 清洗文本:删除项目符号、删除复选框标记,只保留纯任务文字
- 兜底策略:如果没有匹配到任何标准任务,自动拆分句子,识别祈使句(命令式语句)
- 去重:保留文本顺序,剔除重复任务(不区分大小写)
- 返回结果:干净的任务列表
4. 兜底算法:_looks_imperative()
当文本没有标准任务格式时(比如纯段落文字),启动启发式匹配:
- 识别句子开头的动词(add/create/fix/implement/write 等)
- 判定为命令式祈使句 → 视为待办任务
✅ 作用:让脚本适配无格式纯文本,大幅提升适用场景。
四、完整工作流程
1 | |
五、典型使用场景
这个脚本非常实用,常用于:
- 笔记软件:从笔记中提取待办事项
- 会议纪要:自动提取会议行动项
- 文档处理:从需求文档/代码注释中提取任务
- AI 输出后处理:清洗大模型返回的任务列表
- 个人效率工具:整理待办清单
六、关键亮点
- 双模式识别:标准格式任务 + 无格式文本祈使句
- 全自动清洗:输出纯文字任务,无多余符号
- 智能去重:大小写不敏感,保留原始顺序
- 鲁棒性强:兼容各种常见的待办事项书写格式
- 纯本地运行:不依赖网络,速度极快
七、补充说明
脚本中导入了 ollama(本地大模型),但本版本完全没有使用 AI,全程是规则+正则+启发式算法实现,属于轻量高效的文本处理工具。
总结
- 核心定位:通用型任务/待办事项自动提取器
- 输入:任意文本(笔记、纪要、文档、聊天记录)
- 输出:清洗完成、无重复的行动项列表
- 优势:轻量、高效、无依赖、适配绝大多数待办格式
第二步
你的任务是实现一个基于大语言模型(LLM)的替代函数 extract_action_items_llm(),该函数利用 Ollama 通过大语言模型完成行动项提取。
问题一
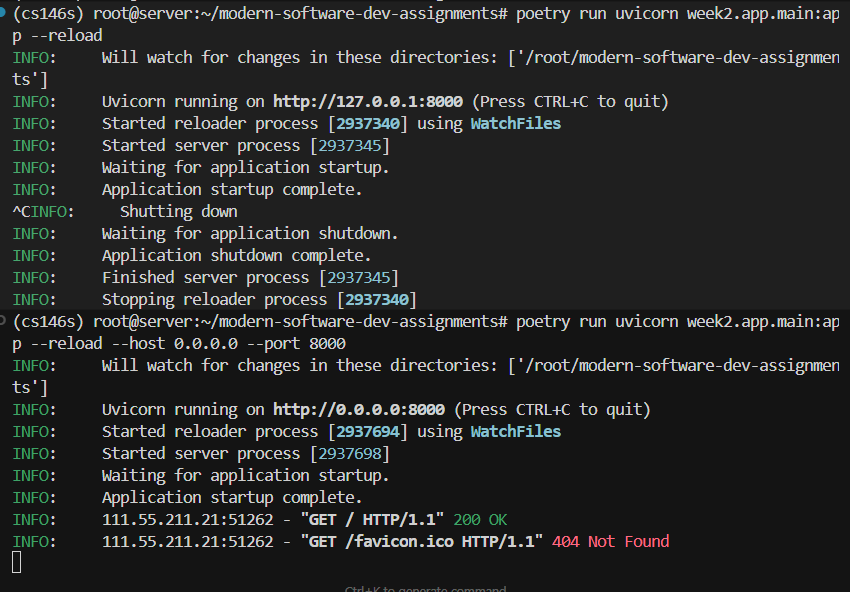
我想问一下 poetry run uvicorn week2.app.main:app –reload –host 0.0.0.0 –port 8000 这条命令运行后,如果我修改了extract.py,前端是否会去调用这个脚本呢?
可以这么理解:
1. --reload 会怎么用你改的 extract.py?
poetry run uvicorn ... --reload 会监视代码文件,你一改 extract.py,Uvicorn 一般会重启后端进程。
重启之后,新请求都会走新加载的 Python 代码。
所以:改 extract.py → 服务重载 → 后端已经用上新版逻辑。
2. 前端会不会“去调用这个脚本”?
不会直接调用 extract.py。
前端只会发 HTTP 请求(例如 POST /action-items/extract 之类),请求打到 FastAPI 路由,路由里再 import 并调用 extract.py 里的函数。
因此:
- 前端不用改,只要还是点同一个按钮、请求同一个接口;
- 你改的是服务端实现,重载后下一次从前端发起的请求就会用新代码。
3. 注意:改的是“被路由用到的函数”才生效
当前默认接口大概率还是调 extract_action_items()(规则/启发式)。
如果你只改了 `extract_action_items_llm()``,而路由没有改成调 LLM 版,那前端再怎么点,也不会自动用到 LLM,除非你:
- 给 LLM 单独加了一个 endpoint 并在前端改按钮去调它,或
- 把现有 endpoint 改成调用
extract_action_items_llm()。
总结:--reload 保证你改 extract.py 后后端会更新;前端仍然是通过 API 间接用到这些代码;是否用到 LLM 取决于路由里实际调用的是哪个函数。